As digital environments grow in sophistication and scope I sense a complementary resurgence of interest in our natural environments as well. Yet ironically features of rampant biodiversity that once survived in tandem with humanity now survive largely in spite of it; many such systems are joining an ever-longer queue to stand in topographic isolation, victims of profligate waste, consumerism or cultivated mono-agricultures. As one example: “The U.S. Department of Agriculture estimates that more than 6,000 varieties of apple trees have been lost since 1900.” To that end, I feel as though any time we can better understand even a fraction of a natural holistic system then we are closer to holding such losses at bay.
There is an unspoken positive side to over-saturation with media, a learning curve that accompanies the environment of selectivity afforded to all of us through technology. For me it comes down several key concepts: organized selectivity, interoperability, a simple design/interface, and ideally uses open-source coding/is free for users to alter. It can be as simple as the Site Search feature that Gigablast offers through its web search interface, where anyone can create a web search box for a blog or site that limits itself to a select pool of (up to) 200 web pages or files, potentially offering greater depth and authority to a guided web search. Or it can be as complex as Google Earth, where a free download allows anyone to view satellite images of any location worldwide
Organization continues to be difficult to achieve, and the reasons for this are stupefying in their complexity. Perhaps the simplest expression of these problems is the lack of a standard for archival and descriptive metadata. And that doesn’t even cover the problems associated with search terms themselves, where a search for buddha can summon results which encompass religion, Hinduism, Zen Buddhism, Osamu Tezuka, films such as Little Buddha, Buddha, or The Light of Asia, Herman Hesse, marijuana, Buddha Bar, meditation, Buddha-Heads, amulets, university and college curricula, etc etc etc.
Many of you probably already know I am referring in part to what Tim Berners-Lee called the Semantic Web. Numerous start-ups and seasoned web veterans are fast at work on developing protocols for just such a machine readable global database. In fact, this year there already are or will be several beta versions from hopeful Semantic Web wranglers; Radar Networks, TextDigger, Theseus in Germany and many many others. W3C has a dedicated Semantic Web Activity News blog that is worth subscribing to just for its window into the official side of things, with technical specs, links to rules for interoperability and notes on large-scale projects.
There is an article in the August 2007 issue of MIT’s Technology Review that inspired these thoughts, seemingly written for a budding librarian obsessed with modern systems of digital and material archiving. Second Earth by Wade Roush is essentially a current assessment of the ways in which we are realizing the Metaverse described in Neal Stephenson’s Snow Crash, or rather the Mirror Worlds hypothesized by David Gerlenter in his eponymous book of 1991. He traces the development of both Linden Lab’s Second Life as well as the wildly popular application Google Earth, and imagines the impact of viable synthesis of the two digital exo-systems.
Imagining an environment that truly simulates the Earth is far easier than realizing it. The estimated computational load alone would necessitate the dedication of, say, the surface of the moon to such a project. As Roush notes, “At one region [65,536-square-meter chunk of topographic architecture] per server, simulating just the 29.2 percent of the planet’s surface that’s dry land would require 2.5 billion servers and 150 dedicated nuclear power plants to keep them running. It’s the kind of system that doesn’t ‘scale well’.”
Regional weather tracking is one enticing reality, as is fboweb.com‘s 3-D flight tracking digital transparency for use with Google Earth. Cyber-tourism is also an intriguing possibility, helping to reduce environmental damage to fragile or endangered locations much in the way that digitization of medieval manuscripts has already done. Some cities are realizing this and Amsterdam for one has provided architectural specifications to Second Life to make visitor’s trips more realistic; Germany supplied plans and images for Berlin’s Reichstag building which now can be visited in exceptional detail by Second Lifers.
“It’s the wiring of the entire world, without the wires: tiny radio-connected sensor chips are being attached to everything worth monitoring, including bridges, ventilation systems, light fixtures, mousetraps, shipping pallets, battlefield equipment, even the human body” Even knee surgery is being improved by such sensors; three micro-sensors are inserted about the knee and GPS triangulation helps the surgeon to avoid unnecessary incisions and invasive exploration, reducing both the number of surgeries (which can be many for a knee) and an outpatient’s convalescence.
When I can ignore my skepticism and paranoia I am enchanted by the possibilities, and a small measure of my hope for humanity is restored. As I said, I have faith in the Big Picture, and the more respect for co-dependent systems we have the closer we come to achieving a sound balance. A friend recently alerted me to Worldmapper, and their beautiful cartographic treasures seem aligned with the emerging Mirror World and with improved Semantic Web capabilities.
Through 366 world maps you are given an idiot’s guide to various global statistics, just by varying the size of geographical regions to reflect raw numbers. For example:
Want to see where people watch the most films?

How about what regions import the most fish and fish products?

Or how about regions with the most forest depletion?
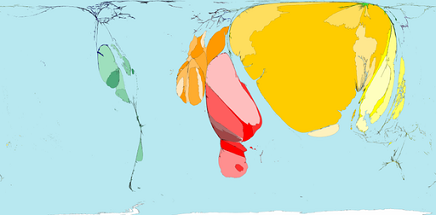
It’s unbelievable, the hypnotic range of cartograms you can find on this site, each with a detailed explanation, citations and even downloadable .pdfs for you to print out and use in any way you wish. Maps about cocoa, disease, disasters, housing, trade, food, health services, literacy, labor, maternity, migrants, sanitation…
It just blows me away each day what one can find on the web, offered free and clear to the known universe.



 Posted by Vaucanson's Duck
Posted by Vaucanson's Duck 













